I attended PGConf NYC 2015 on March 26-27. Going to conferences is awesome, in my opinion, because there is an amazing collection of minds available. Minds interested in the same topic you are, which in the nerdosphere(TM) is sometimes hard to come by.
Before getting started discussing my favorite talks, I would like to send a quick thank you to the conference sponsors, organizers, and venue. Organizing any conference, especially a successful one, is a lot of hard work. Double props to both the organizers and the venue (New York Mariott Downtown) for being able to cater to people with special diets – in addition to the executive chef Ed Pasch speaking to me personally to check on my dietary restrictions/allergies and making a meal safe for me to eat, I also saw a kosher meal and a vegan meal for two other guests. I’m so used to having to travel with my own food that this was a very pleasant surprise.
My Favorite Talks
Now for the good stuff! Amongst all the amazing talks I attended on both days, I did have a a few favorites:
- Favorite “inspiration” talk: Building a ‘Database of Things’ with Foreign Data Wrappers
- Favorite “new feature” talk: JSON and PostgreSQL, the State of the Art
- Includes a comparison between PG 9.4 and MongoDB 3.x
- Favorite “tricks” talk: A TARDIS for your ORM – application level time travel in PostgreSQL
- Favorite “upcoming feature” talk: Row Level Security
Since all of these talks were very informative, and there are several, I’m only going to scratch the surface of what I enjoyed from each. I will be linking to the lecture slides as available and I encourage everyone to take a look.
Building a ‘Database of Things’ with Foreign Data Wrappers
First stop: this talk I mentally dubbed the “fun” talk, because nothing beats having someone control a lights display with PG commands at a PG conference. In order to make this work, Database of Things speaker Rick Otten used Philips Hue light bulbs and, of course, PG’s foreign data wrappers (FDWs). As a point of interest, he used multicorn, which is a PG extension for developing FDWs in Python.
Briefly: the purpose of the talk was to explore the usefulness of FDWs in PG. For the uninitiated, FDWs are used to access data from a “foreign” database. For example, you may need data from an Oracle database, or even a flat file. To access the data you would use the appropriate FDW. FDW read-only support was added in PG 9.1 and write support was added in 9.3 in compliance with the SQL/MED standard.
Why I liked this talk: App ideas! I’m a big fan of “the internet of things” and making our devices “smarter”. For example: you could write a “smart house” application that does things like open your garage when your car approaches (no garage door opener button required), turns on the light in the garage, and then turns on the light of the room you would enter in your house. You could also program some other basics, like light timers and such. Pranks would be awesome too – turning lights on and off, changing their color, making “annoying” sounds. Convince your [insert close friend/relative here] that his/her house is haunted for a day! Or, more benignly, make really awesome outdoor holiday displays (I’m looking at you Halloween and Christmas).
Lecture slides are in the extra directory in the project repo on GitHub. The PG wiki also has a well written article about FDWs here.
Speaker on Twitter
JSON and PostgreSQL, the State of the Art
I really like this talk because it touches on something I am working on as a learning exercise – JSONB.
JSONB is the “JSON Binary” datatype was introduced in version 9.4 (the latest release as of this post). In a side project I am working on, we are actually working on using the database for more. In particular, we are loading JSON data from an API directly into the database and then manipulating that data in PG for use in various tables. The goal of this is to really grok how to maximize PG’s potential and performance with stored procedures.
Something this talk showed that I was not previously aware of is that JSONB containment (@> / <@) is not recursive. Here are a couple example statements from the slides:
postgres=> SELECT '{"a": 1, "b": 2}'::jsonb @> '{"a": 1}'::jsonb;
postgres=> SELECT '[1, 2, 3]'::jsonb @> '[1, 3]'::jsonb;
postgres=> SELECT '{"a": {"b": 7, "c": 8}}'::jsonb @> '{"a": {"c": 8}}'::jsonb;
postgres=> SELECT '{"a": {"b": 7}}'::jsonb @> '{"b": 7}'::jsonb;
postgres=> SELECT '{"a": 1, "b": 2}'::jsonb @> '"a"'::jsonb;
Of these statements, the first three return true and the last two return false. I found this interesting because I initially assumed all five statements would return true and I could definitely see myself making an error implementing this.
Lecture slides are available here.
Speaker on Twitter
Secondary concept: How does MongoDB compare to postgreSQL?
The JSONB talk included something else that I found interesting: a performance comparison between PG and Mongo.
Historically, I’ve heard a lot of negativity about Mongo. In fact, the few times I’ve worked with Mongo 2.x I’ve found it to be quite painful, for example I’ve run into issues with Mongo silently failing on more than one occasion. Hard to troubleshoot. On top of that, typically I’ve seen that PG outperforms Mongo 2.x by quite a large margin by reviewing posts like these.
To compare how PG and Mongo handled JSON and JSONB transactions, this speaker did several tests with both 4 and 200 JSON fields using MongoDB 3.x. Although there are some tests where PG is still reigns supreme:
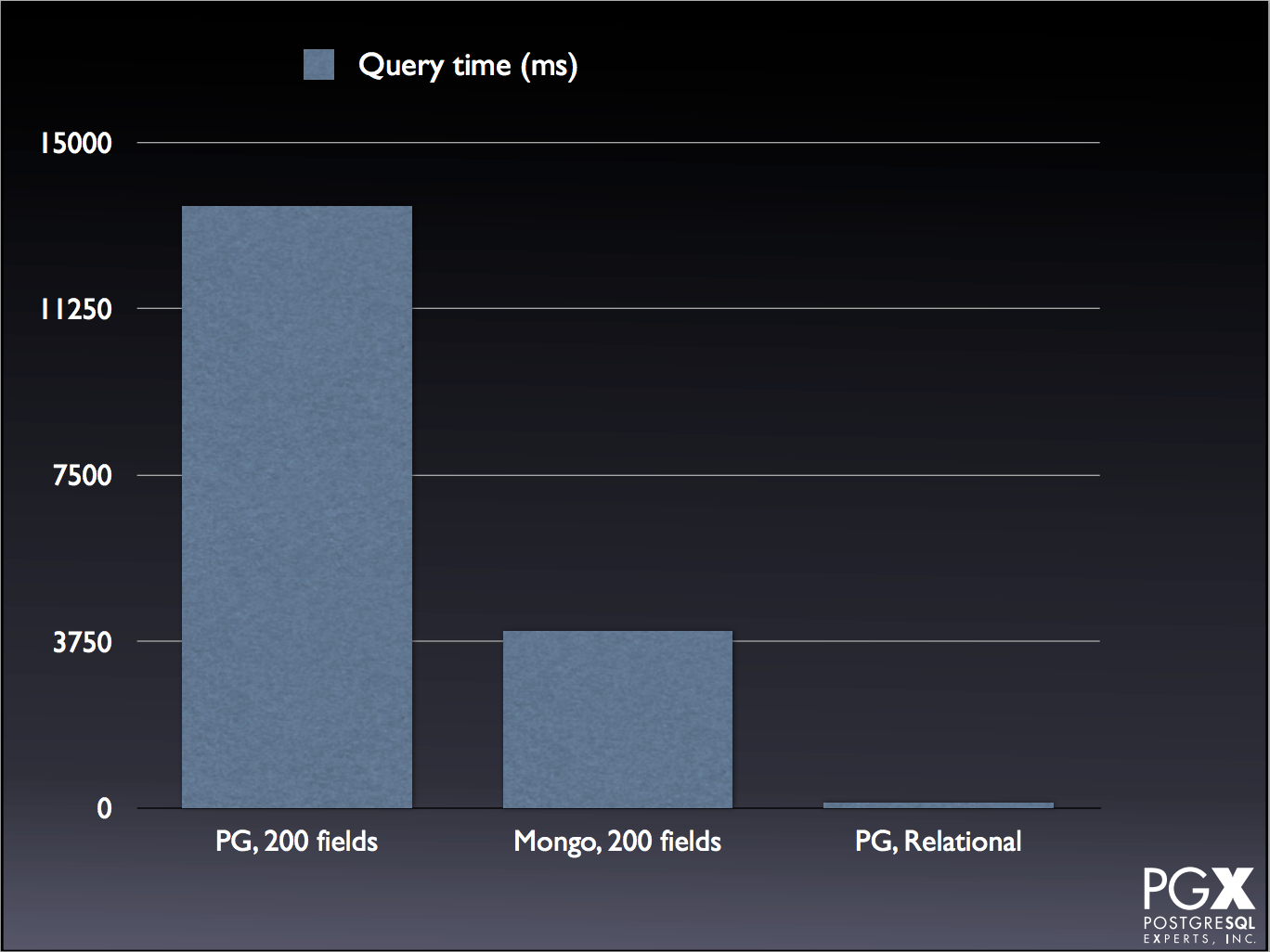
There are several cases where Mongo is comparable, or even exceeds, PG performance:

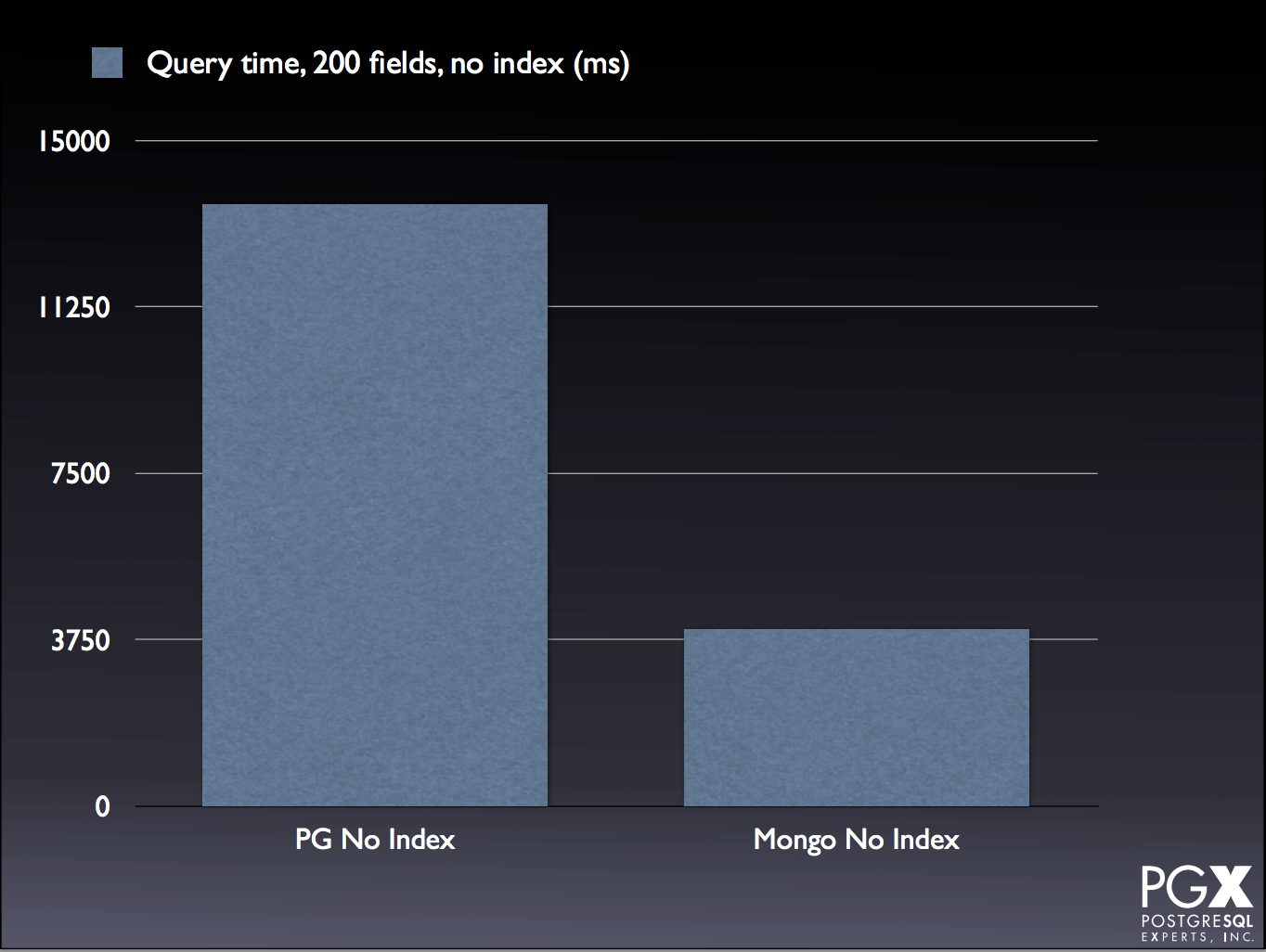
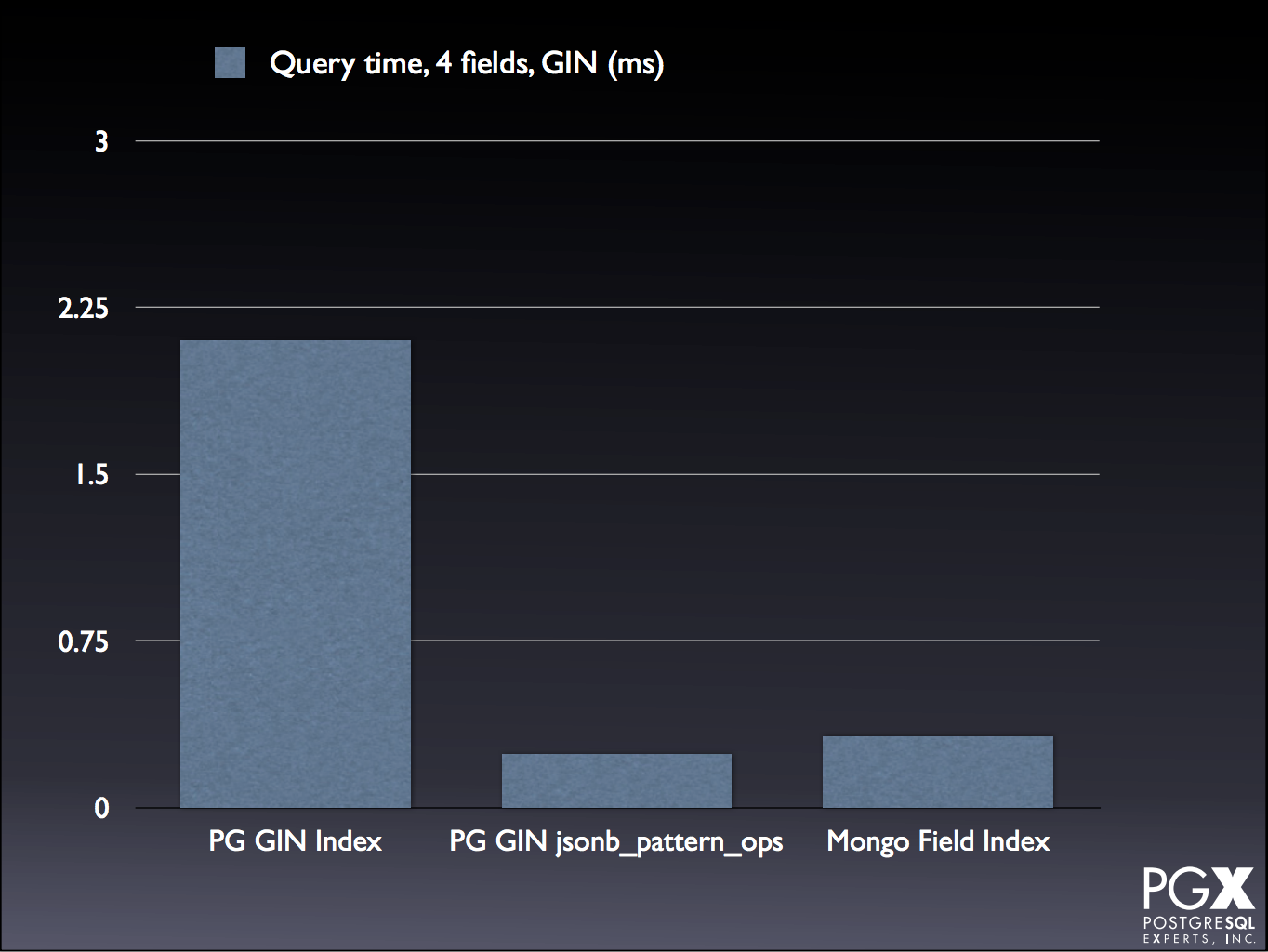
For the tests and explanations, take a look at the slide deck, starting on slide 75.
A TARDIS for your ORM – application level time travel in PostgreSQL
As a Doctor Who fan, I just want to take a moment to say that if the talk didn’t live up to my excitement from the title alone, I would have been disappointed.
Luckily, it did!
The challenge this solution was designed to solve was reproducing report runs in a system that held a lot of statistical data that included personal information. More granularly, the solution was originally engineered to be able to reproduce incorrect reports.
By example: you have a row of data that was entered as {Jane, Doe, Dec-25-1986, F, Security Guard} on Jun 1 2015, but was then corrected to {Jayne, Doe, Dec-25-1986, M, Security Guard} on Jun 20 2015 (too soon?). All reports run between Jun 1 and Jun 19 2015 would include the first result, and all reports thereafter would include the corrected result. If some day in 2016 you needed to replicate the report as it was run on Jun 15 2015, you would need to have the uncorrected result returned.
So, what did they do?
They built a solution that included PG (of course!) as well as JBoss/Hibernate. In order to keep their old data they made history tables and included a column with a range type to keep track of when specific data points were valid. In order to update the tables, they wrote a series of trigger functions that handle whether data/tables are being updated or deleted and update the corresponding date ranges. Then they created a “time travel” schema and a used a schema search setting to determine what views (autogenerated) are returned. To determine which reports contained a specific person, they used full reporting query logging with “time travel”.
Some caveats/requirements:
Lecture slides are here.
Speaker on Twitter
Row Level Security
I’m really excited about this feature, confirmed for release with PG 9.5. The scoop on this one is that this is a security feature that can restrict what rows are returned in a dataset. This is done by creating a security policy (CREATE POLICY) and applying it to your tables. Thinking forward, the team has also made it possible to add a security policy to an existing table (using ALTER TABLE, ENABLE ROW LEVEL SECURITY).
I think the main reason this excites me is because of a past job I had working as a DB admin at a company that handled data for clinical data trials (read: patient data, HIPAA, paperwork, security policies up the wazoo). As a point of interest that company uses Ingres, which I’ve found amuses PG fans more so than most ;)
Now that I’m thinking about them, I could definitely see this feature being useful in that setting (if they were using postgres). For example, let’s say you have 3 groups tracking breast cancer data. Maybe they are gathering the same data, so you could have one table but you want to make sure that no one can see the others’ data. Enter RLS. You could restrict which rows are available to each group, so that they only see their own data when they run queries :D
Although the link to the PGConf Row Level Security presentation isn’t available yet, he did give a similar presentation a few months ago. Those slides are here. The slides are filled with examples for how to CREATE, UPDATE, DROP/DELETE, ENABLE, DISABLE, etc. – so I highly recommend reviewing them. You may also want to reference the PG developer docs on their wiki here.
Speaker on Twitter
Written with StackEdit.
Link to work post